Hi! I'm Chin-Jou Li
Hi! I'm Chin-Jou Li
Home
Publications
Projects
Contact
CV
Light
Dark
Automatic
Multimodal
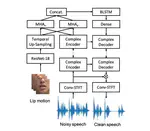
Deep Complex U-Net with Conformer for Audio-Visual Speech Enhancement
Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. We …
Shafique Ahmed
,
Chia-Wei Chen
,
Wenze Ren
,
Li, Chin-Jou
,
Ernie Chu
,
Jun-Cheng Chen
,
Amir Hussain
,
Hsin-Min Wang
,
Yu Tsao
,
Jen-Cheng Hou
PDF
DOI
EGO4D Audio-Visual Speaker Diarization Challenge 2023
Utilized self-supervised embeddings and people tracking algorithms to identify who and where the speakers are in egocentric videos.
PDF
1st COG-MHEAR AVSE Challenge
A DCCRN-based Audio-visual Speech Enhancement Approach. Ranked 3rd place.
PDF
Cite
×