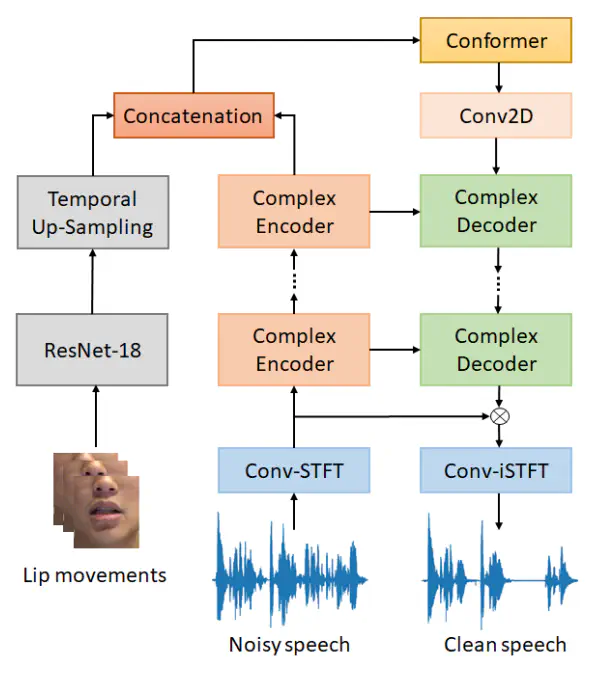
 Architecture of the proposed DCUC-Net
Architecture of the proposed DCUC-NetAbstract
Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. We introduce a novel audio-visual SE approach, termed DCUC-Net (deep complex U-Net with conformer network), which leverages complex domain features and a stack of conformer blocks. The encoder and decoder of DCUC-Net are designed using a complex U-Net-based framework. The audio and visual signals are processed using a complex encoder and a ResNet-18 model respectively, then fused by conformer blocks and transformed into enhanced speech waveforms via a complex decoder. The conformer blocks consist of a combination of self-attention mechanisms and convolutional operations, enabling DCUC-Net to effectively capture both global and local audio-visual dependencies. The results demonstrate the effectiveness of DCUC-Net, as it outperforms the baseline model from the COG-MHEAR AVSE Challenge 2023 by a notable margin of 0.14 in terms of PESQ. Additionally, the proposed DCUC-Net performs comparably to a state-of-the-art model and outperforms all other compared models on the Taiwan Mandarin speech with video (TMSV) dataset.
Li, Chin-Jou
1st-year Master’s student @ CMU LTI
My love for languages brought me to computer science. I want to help people communicate and understand each other better using language technologies!