EGO4D Audio-Visual Speaker Diarization Challenge 2023
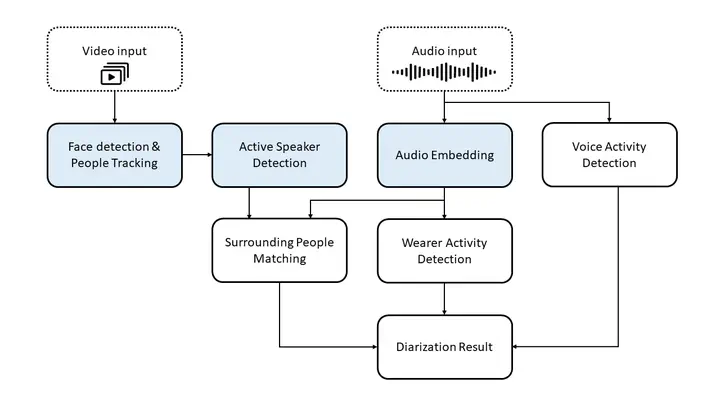 Our model overview. We enhanced the blocks in blue.
Our model overview. We enhanced the blocks in blue.This is a report of the audio-visual speaker diarization (AVD) task at EGO4D Challenge 2023.
The audio-visual diarization task focuses on tackling the problem of ’who spoke when’ in a given video. Inspired by the recent success of self-supervised learning (SSL) in speech processing and audio-visual applications, We wonder if self-superivsed embeddings (SSE) from the SSL models can benefit the AVD task as well.
Our approach was based on the baseline system. We replaced three building blocks with more advanced modules: face detection and tracking pipeline, AV-HuBERT based model for active speaker detection, and a pre-trained HuBERT model is used for generating audio embeddings.
On the validation data, frame-level prediction’s accuracy was increased from 79% to 84%, and a gain of 3% at diarization error rate is observed.
Li, Chin-Jou
1st-year Master’s student @ CMU LTI
My love for languages brought me to computer science. I want to help people communicate and understand each other better using language technologies!