1st COG-MHEAR AVSE Challenge
 Our speech enhancement model combining lip motion and wave form.
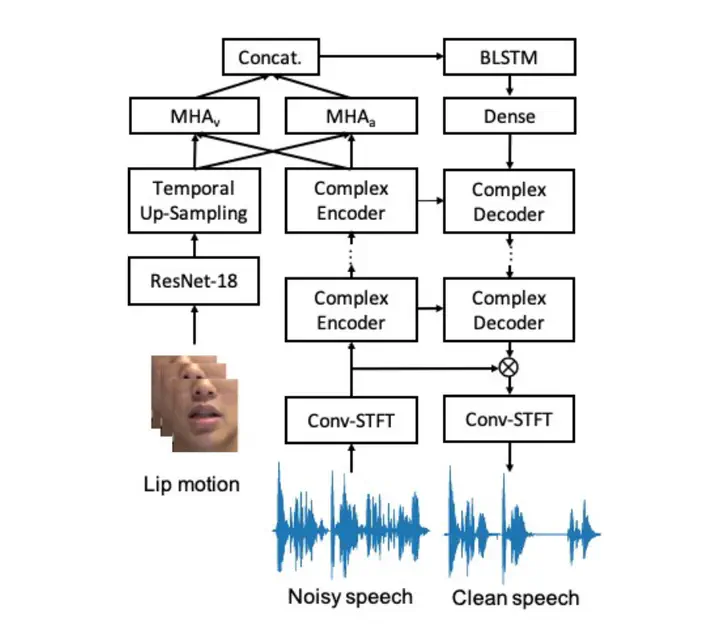
Our speech enhancement model combining lip motion and wave form.This is a report for the 1st COG-MHEAR AVSE Challenge. Our model ranked the third in the competition.
In this challenge, the goal is to denoise the audio from a given video. Our proposed approach is based on deep complex convolution recurrent network (DCCRN), which has been shown to be effective for speech enhancement (SE) by predicting target complex spectrum via complex-valued operation. We incorporate additional visual information (e.g., lip motion) as an audio-visual speech enhancement (AVSE) approach for the 1st COG-MHEAR AVSE Challenge.
Noisy speech is converted into complex spectrum and processed via a U-net like complex encoder-decoder architecture, where the latent representations are processed with a BLSTM network. The visual features and the speech features are fed into cross-attention modules composed of multi-head attention (MHA).
Our model outperforms the baseline model with a 40.7% and 23.8% improvement in perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI), respectively.
Li, Chin-Jou
1st-year Master’s student @ CMU LTI
My love for languages brought me to computer science. I want to help people communicate and understand each other better using language technologies!